データの標準化(標準化)と一元化。 配給は忘れ去られた新しい管理ツールです
データの標準化(標準化)と一元化
正規化された (標準化された) データ。多くの問題では、元の観測値 (i = 1, 2,.... n) から正規化された (標準化された) 観測値に移行することが便利であるか、必要ですらあります。これについては、以下で紹介します。 私たちが取得したデータに基づいたデータがあるとしましょう
![]()
標準化された (標準化された) の形式のデータと呼ばれます。
– 条件を満たす無次元量
正規化されたデータの算術平均がゼロであることを示してみましょう。
そして分散は 1 に等しい:
さらに、正規化された値がゼロより大きい (.r* > 0) 場合、観測された値は平均よりも大きくなります。 (バツ; >x)。もし バツ" < 0, то バツ、< х.
データの標準化(正規化)が必要 初期多くの多次元統計手法を使用したデータ変換 - 特徴空間の次元の削減 (階乗分析、成分分析、第 5 章を参照)、オブジェクト分類 ( クラスター分析の章を参照してください。 6) など、特に変数の大きさが大幅に異なるスケール (ミクロン単位から数十億単位) で測定されている場合。
統計パッケージでの普及と需要により、正規化 (標準化) 手順は通常メニューに含まれています (図 1.31)。

米。 1.31。 パッケージメニューのデータ正規化(標準化)プロシージャの呼び出しSTA TISTICA (スタットソフト)
データの統一(スケールの統一)。積分一般化インジケーターを構築する場合、データの正規化で望ましい結果が得られない状況がよく発生します。 たとえば、平均余命、乳児死亡率、失業率という 3 つの初期変数を含む、国 (地域) の生活の質の統合指標を構築する必要があります。 さらに、これら 3 つの指標を 1 つのスケール (たとえば、0 から 1、または 0 から 0 までの値) に変換することもできます。 N)、次の計画の変数の解釈で矛盾が生じるでしょう。
最初の変数である平均余命は、その値が高くなるほど、その国(地域)での生活の質が高くなるという事実によって特徴付けられます。 逆に、2番目の変数である乳児死亡率は、その値が増加すると生活の質を低下させます。 3 番目の変数 – 失業率 – には独自の最適値があります (およそ 5% 経済の正常な機能と発展を保証します)。 そして、3 つの特性すべてを 1 つの統合指標に組み合わせると、結果の指標を適切に解釈できなくなります。 これが高いほど平均余命は長くなり(良くなり)、乳児死亡率は高く(悪くなり)、失業率は高くなります(明確ではありません)。 このような問題を解決するには、データ分析時にこれを行う方法があります。これは、積分指標の構築に関与するすべての変数を単一の統一されたスケールにまとめるというものです。
統一スケール– さまざまな変数から積分指標を構築する際に使用されるスケール。0 から N までの値をとり、 統一システム解釈: 統一スケール上の変数の値が高いほど、積分指標の値も高くなります。 で N= 0 から 1 までのスケールが得られます。
最初のタイプの変数 (指標が高いほど良い (平均寿命)) は、次のように統一された尺度に換算されます。
どこ Xj – i 番目の観測値の変数の値。 amin と amax は、それぞれ変数の最小と最大の観測値です。
この式によれば、 バツ t – amin、次に a" = 0、および if.g、 – apt、その後 x] = N、それらの。 変数 a の値が大きいほど、統一スケール a* におけるその値はより高く (より良く) なります。
2. 2 番目のタイプの変数 - 指標が高いほど悪い (乳児死亡率) - は、次のように統一された尺度に換算されます。
この式によれば、a, = at|1) の場合、th バツ = ん、そして、a, - = a「彼ら」の場合、a* = 0、つまり 変数 a の値が大きいほど、統一スケールでの値は低くなります (悪くなります)。 バツ/。
3. 3 番目のタイプの変数 - 指標には特定の最適な aopt があり、この値が最良であり、そこからの偏差が大きいほど悪くなります (失業レベル) - は、次のように統一された尺度にまとめられます。
この式によれば、 バツ t = そうですね、それでは バツ] = N. a の場合、最大値があります 逸脱の可能性 otashp の場合、a," =0。たとえば、(ashakh – a,sht) > > (aOMT-amin) および a, = atah の場合、a" =0。 したがって、変数 a の値が最適値から離れるほど、統一スケールにおける a* の値は低く (悪くなり)、より大きくなります。 より近い値そして、これが最適であればあるほど良いのです。
なぜインジケーターの正規化が必要なのでしょうか?
通常、彼らは特定の品質の深刻さを数値で説明しようとします。 ほとんどの場合、この数値 x はポイントの合計として形成されます。 これがどの程度合法なのかは別の問題です。 このような数値 x が得られ、意味があると仮定します。
通常、x は、ある最小値 x min (品質の欠如を反映する) からある最大値 x max (極端な発現、存在、表現など) まで変化します。
これを取得すると、2 つのオブジェクトを比較する問題が解決されますが、それはこのインジケーターに従ってのみです。 しかし、ここでも状況はあまり良くありません。 インジケーターがどのような制限内で変化するかを常に覚えておく必要があります。 そして、これらの範囲は非常に多様です...また、特定の値が範囲の端または中央にどれだけ近いかを評価します。 一般的に、それは純粋に面倒なことです。
もし 私たちが話しているのは 2つの異なる指標の比較については、問題は完全に海上にあります。 もちろん、品質を直接比較することはできません。 これを行うには、比較される数値が無次元である必要があります。 しかし、それはまさに、通常次のように解釈される指標です。 表現の程度ある程度の品質。 そして今、あなたはこれを比較することができます! ただし、これを行うには、2 つのスケールの始まりと終わりが一致するように、それらを 1 つのスケールに合わせる必要があります。
しかし、なぜこの2つだけなのでしょうか? すべてのインジケーターに対してこの変換を実行してみましょう。 それは呼ばれています 正規化(混同しないでください 正規化!)。 その後、さまざまな方法で取得されたさまざまな指標を比較できます。
2. インジケーターの種類
オブジェクト (または回答者) のさまざまな数値特性により、次の 2 つの大きなクラスに区別できます。
- 単極構造、特定の品質の存在の程度(強度、深刻さなど)のみを表現します。
- バイポーラ品質の存在感だけでなく、その「方向性」も反映します。
3. 単極インジケーターの正規化
科学では、量が 0 から 1 の範囲に正規化されることが長い間常識でした。
これを行うには、変換関数 y=f(x) に次のプロパティが必要です。
y(x分)=0; y(x 最大)=1; dy/dx>0 (1)
このようなプロパティを持つ関数は次のようになります。 正規化に使用されます。 たとえば、 x max の場合、次の関数を選択できます。
![]()
適切な関数を選択することで、推定値の歪みによるさまざまな影響を考慮できることが簡単にわかります。 たとえば、回答者が極端な評価をする傾向があります。 この場合、回答者の性格やステータスなどの特性を考慮して、回答者ごとに異なる変換関数を適用する必要がある場合があります。 このような関数の近似グラフを図に示します。 1.

米。 1. 正規化関数グラフ
最も一般的に使用される線形変換は次のとおりです。
![]() (2)
(2)
x の増加が品質 A の重大度の増加と、他の品質 B の程度の低下の両方を表すと仮定すると、品質 B の正規化された尺度は、単に差 y´=1–y になる可能性があります。 これらは、たとえば、関連する性質「近さ」と「距離」です。 それらの計量化により、これまでほとんど理解されていなかったが、非常に明確な相補性、さらには対立関係が明らかになります。
4. 双極性インジケーターの正規化
通常、このような指標は、相互に前提とし、対義的な 2 つの単極性 A と B を「接着」したものです。
多くの場合、B は単に A の否定であり、その逆も同様です。 たとえば、意味論的な差分スケールはこの原則に基づいて構築されています。 ただし、このような違いのペアは、対義語の辞書で確認する必要があります (たとえば、「陽気」という単語の 2 つの対義語、「悲しい」と「暗い」はまったく同義語ではありません)。
対応する値の正規化には、「 ポジティブ» y 軸方向。 そのような 恣意的に強度が増加するスケールの極を選択します 増加しているとみなされるやあ。 反対極は自動的に「」になります。 ネガティブ」 この背後にはモダリティ (公理的評価) はないことを強調しておきます。確立された意味論的なステレオタイプのみが役割を果たすことができ、それ以上の役割を果たすことはできません。
値 x で両方の性質の発現の度合いを評価します (たとえば、「とても好き」または「少し嫌い」など、適切な指定を使用します)。 正規化は条件(1)を満たす任意の関数で行うことができます。 特にこれは、 そして線形変換:
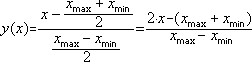 (3)
(3)
明らかに、y[–1; +1]。
式 (2) と式 (3) はどちらも、y=k・x+b の形式の線形変換を記述しています。 したがって、すべて 統計的結論 x 値と y 値を基準とした 完全に一致する.
5. スコアリングスケールの特徴
スコアリング スケールを使用する場合、見落とされがちないくつかの微妙な点があります。
- 特定の指標に関連するすべての質問に対する答えがない場合があります。 理由はさまざまです。単純に答えが与えられていなかった、答えを入力またはエンコードしたときにエラーがあった、...要するに、答えに漏れがあるということです。
- ほとんどの場合、スコアは特に回答番号と同じになります。 そして最低点は1となります。
- 一部の質問については、他の質問とは異なる階調数の回答を使用したいと思います。 しかし、彼の貢献は別の方法で考慮される必要があります。
ポイント スケールを正規化するときは、x = S を受け入れるだけで済みます。S は、受け取った回答に基づいて得点されたポイントの合計です (ただし、そうではありません)。 質問された!)。 したがって、S min と S max は最小値であり、 最高額受け取った回答に基づいて得点できるポイント。
考慮中の基準の値自体は、特性間の関係を評価するのには適していません。なぜなら、これらの値は、サンプルサイズや、一般的に言えば、測定された接続の強さに関連して本質的にランダムである他の状況に依存するためです(約このような状況 話しましょう下に)。 したがって、元の頻度テーブルのセルに 10、20、30 のオーダーの値が含まれている場合、たとえば 30 に等しい基準値は、接続の可能性が高いことを示し、同じである可能性はわずかであることを示します。問題の周波数が 1000、2000、3000 などの場合。 このような場合、基準の見つかった値を一定の正規化する必要があります。これは、(関係を評価するための) ランダム要因への前述の依存を排除するような変換です。
ここでは、社会学で使用するときによく生じる基本的な点について話していることを強調します。 いろいろな種類統計基準、指標など 使用されるインジケーターが研究対象の現象に関してランダムなものを反映しているかどうかを確認し、そのような反映が存在する場合はインジケーターの適切な正規化を実行することが常に必要です。
正規化された係数が -1 から +1 に変化するような方法で、前述の正規化と同様の正規化を実行するのが通例です (検討中のインデックスを使用して調査対象の現象の正と負の方向を対比することが意味がある場合は、私たちの場合 - コミュニケーション)、または 0 から 1 (現象の正と負の方向を識別することが意味のある場合)。
すべての係数を同じ間隔にすることは、それらを比較できることを保証するために必要な条件ではありますが、十分な条件ではないことを強調しましょう。 そのような削減が行われない場合、比較は明らかに不可能です。 しかし、たとえそれが実行されたとしても、比較は無意味であることが判明する可能性もあります。 これについては 2.3.5 項で説明します。
必要な正規化にはさまざまなアプローチがあります。 最も有名なものは、「カイ二乗」基準をよく知られた係数に変換するもので、通常、最初にそれらを提案した著者の名前 (ピアソン、チュプロフ、クラマー) の名前で呼ばれます。 これらの係数には、名前付き姓の最初の文字に対応する永続的な指定があります (チュプロフの係数はドイツ語の tsch に対応し、クラマーの係数は、ドイツ語の音「k」を表す文字の違いが知られているため、2 つの指定があります) さまざまな言語):


これらの係数のいくつかの特性について説明しましょう。 通常、文献で指定されているものから始めましょう。
すべての係数は 0 から 1 まで変化し、特徴が完全に独立している場合 (上記の意味で) 0 に等しくなります。 カイ二乗検定と同様、これらの指標は私たちの特性に関して対称的です。指標の助けを借りても、分析に基づいて従属変数と独立変数を区別することは不可能であり、どの変数がどの変数に「影響を与える」かを言うことは不可能です。
通常、ピアソン係数 P (文献で最初に提案されたもの) の欠点として、その最大値がテーブルのサイズに依存することが挙げられます (最大 P は c = r で達成されますが、最大値はカテゴリの数の変化に応じて変化します。c = 3 では P の値は 0.8 を超えることはできず、c=5 では P の最大値は 0.89 などです。[解釈と分析..., 1987. P.31] )。 当然のことながら、これにより、異なるサイズのテーブルを比較するときに困難が生じます。
社会学者向けの文献ではほとんど考慮されていない次の重要な事実に注意してください。
考慮されている係数の多くの特性は、社会学にとって必ずしも受け入れられるわけではない 1 つの仮定が満たされた場合にのみ証明できます。つまり、それぞれの名目上の特性の背後には、特定の潜在的な (隠れた) 連続的な量的 (数値) 変数があるということです。
使用されている用語について少し脱線しましょう。 「変数」という用語の 3 つの定義はすべて明確にする必要があります。 「潜在的」という用語は、ここではやや恣意的に使用されています。 通常(社会学的測定理論、たとえば因子分析、潜在構造分析、多次元尺度法)では、潜在変数は、その値を直接測定することがまったくできない特性として理解されます(たとえば、問題に直接対処することによって)。回答者)。 最も直接的な方法で変数の値を測定します。 しかし、名目スケールは得られますが、これらの値に対応する実際のオブジェクトのプロパティ間には、間隔スケールの使用について話すのに十分複雑な関係があると想定しています(オブジェクトの「豊かさ」との関係について)。経験的オブジェクトとスケールのタイプの間の実際の関係。これらのオブジェクトをスケールする際に使用されます。たとえば、[Kliger et al., 1978; Tolstova, 1998] を参照)。
ここでの「連続」という用語は、任意の有理数がこの変数の値として機能するという意味で使用されています。
伝統に従って、私たちはその値が間隔スケールのタイプよりも低くないスケールで取得される変数を「定量的」と呼びます(「定性的 - 定量的」という用語のそのような使用に対する私たちの態度は、パート I のパラグラフ 4.3 ですでに説明しました)。 このようなスケールでは、原理的には任意の有理数が何らかのオブジェクトのスケール値になることがわかります。 したがって、「定量的」と「継続的」という用語は、多くの場合同じ意味で使用されます。)
したがって、各名目特性は、その変化の範囲を任意に間隔に分割した結果として、何らかの定量的な特性から得られると考えられます。その数は、名目変数の値の数に等しいです。 そして、アンケートで興味のある質問を回答者に尋ねることで、考慮中の変数の変化の全範囲をいくつかの区間に分割し、その区間のどれに該当するオブジェクトが評価されているかを回答者に示すよう強制しているようです。位置しています。 各区間内では変数の値は区別できなくなりますが、区間間では一致と不一致の関係のみが決定されます(名目スケールの主な特性)。 研究者がこの種の 2 つの変数を扱う場合 (たとえば、ペアごとの関係に関心がある場合)、通常、対応する二変量分布の正規性も仮定されます。
これらはまさに、今世紀初頭にピアソンが係数を導入したときに遵守した仮定でした。 彼は、P が潜在変数間の通常の相関係数の限界値に等しいことを証明しました。この係数は、考慮中の特性の階調数が無制限に増加すると、この相関係数に向かう傾向があります。 この仮定がなければ、係数 P のそのような特性をどのように解釈できるかが完全に不明確になることは明らかです。
ピアソン係数の指摘された欠点 (分割表のサイズに対するその最大可能値の依存性) を修正するために、チュプロフは彼の名前にちなんで名付けられた T 係数を導入しました。 しかし、T も c=r でのみ 1 に達し、c¹r では 1 に達しません。 テーブルの種類に関係なく、Cramer 係数 K は 1 に達する可能性があり、他の場合には Cramer 係数と Chuprov 係数が一致します。
文献でよく言及されている、考慮中の係数の特性をリストしました。 めったに言及されない特性の中で、すべての係数に固有のもう 1 つの欠点、つまり、分析された分割表の周辺周波数の比率に対する係数の大きさの依存性について言及することができます (非常に強調しています)。 大事なポイント– 理論的な頻度を計算するとき、私たちはその「一般的な」値を扱っていると信じて周辺和を使用しますが、一般的に言えば、それは必ずしも現実に対応するとは限りません。
カイ二乗検定を使用して公称特性間の関係をどのように測定できるかについては、[Eliseeva、1982; エリシーヴァ、ルカビシニコフ、1977 年、82-89 ページ。 解釈と分析...、1987、31-32 ページ。 ラクティン、トルストヴァ、1990年。 パニオット、マクシメンコ、1982、p.65-84。 Sociologist's Workbook、1983 年、169-172、190 ページ (169 ページでは、名目変数の統計的独立性の場合に対応する分割表の頻度である、そのような理論的頻度について話しているという事実を考慮に入れて)検討中の); 統計的手法...、1979 年、117-120 ページ。 トルストヴァ、1990a、p.54-57]
K. Thomas の有名なテクニックの例を使用して、規範を使用することの重要性を説明しましょう。 その中で、紛争状況における行動の支配的な戦略についての結論が数値データに基づいて作成されていることを思い出してください。 つまり、各スケールの合計ポイントを計算した後、最も高いスコアを持つスケールを特定する必要があります。 紛争状況では、規模に応じた戦略が優勢であると解釈されます。 計算された統計は、絶対値でのスケール評価の平均値が異なることを示しています。 男性の場合は 5.25 ポイントから 7.25 ポイント、女性の場合は 3.71 ポイントから 7.65 ポイントの範囲で変化します (表 11 を参照)。
テーブル 11. トーマス法のスケール評価の一次統計
|
男性 (n=56) |
女性 (n=71) |
|||||||
|
戦略 | ||||||||
|
積極性 | ||||||||
|
協力 | ||||||||
|
妥協 | ||||||||
|
回避 | ||||||||
|
コンプライアンス | ||||||||
注記。
平均 - 平均値;
950% および +95.0% - 平均値の信頼区間。
最大の平均値が強調表示されます。
したがって、ロシアのサンプルで得られた(またはロシアのサンプルでテストされた)規範的なデータを考慮に入れないと、結果を解釈する際に誤った結論に達する可能性があります。 実際、男性も女性も回避戦略を好む傾向があります。 このテクニックのマニュアルには、5 つの戦略のうちの 1 つの優位性が個人の異文化的特性であるとは書かれていません。 文脈から、著者が 5 つの戦略のそれぞれについて優先確率が等しいという仮定に基づいて話を進めていることが理解できます。 スケール指標間には統計的に有意な相関関係があるため、5 つの戦略のそれぞれに従う確率が等しいということはほとんど不可能です。 このような状況では、値の分布の性質に関する規範的なデータや情報がない場合、サンプルに対して計算された統計に依存する方がより信頼性が高くなります。 特に、いずれかの戦略の優位性の重大度を評価するには、シグマと信頼区間を使用します。 男性と女性の基準を別々に計算することが望ましいことを付け加えておきます。 提示されたデータによると、5 つのスケールのうち 2 つで、指標が性別間で大きく異なることが明らかです。 グループやサブグループを比較する場合、この性特異性は影響を無視できない変数となる可能性があります。
他の場合でもノルムを計算することをお勧めします。 データ収集中に得られた実験タスクのパフォーマンスの初期(一次)評価は、その後の作業で使用するのが必ずしも便利であるとは限りません。 それらは何らかの方法で変換されます。 最も一般的な変換は次のとおりです。 センタリングと正規化標準偏差。 センタリングは、特定の特性の分布の平均値がゼロになる、特性の値の線形変換として理解されます。 スケールの方向とその単位は変更されません。
標準化の本質は、別のスケール、つまり標準化された測定単位への移行です。 テスト結果を標準化する場合、ほとんどの場合、標準偏差を使用して正規化が実行されます。 標準化は、テストのスコアの分布が見た目に正常またはそれに近い場合に実行されます。
心理学では、正規分布に基づいた多数の尺度があり、 さまざまな意味 Mと。 たとえば、知能偏差スケール IQ では、M=100、 =15、 ウェクスラースケールでは M=10、 = 3。実験で測定されたさまざまな特性の分布は、M と の値が異なります。 得られたさまざまな特性の一次推定値を同じ M と の分布に変換することで、それらの変動を評価および比較する機会が増えます。 正規化された偏差を使用すると、これが可能になります。 正規化された偏差は、このオプションまたはそのオプションが変動する特性の平均レベル (算術平均) から何シグマ離れているかを示し、次の式で表されます。
ここで、V は属性の値 (初期スコア) です。
正規化された偏差を使用すると、取得した値をグループ全体と比較して評価し、その偏差を重み付けすると同時に、名前付きの値から解放されます。 取り除くために 負の数結果として得られる t 値に任意の定数を追加できます。 操作するすべての番号の桁数が同じであると便利です。 これらを考慮すると、T スコア スケールは非常に便利です。 このスケールでは、M = 0 の正規分布が受け入れられます。 =10。 再計算では、50 に等しい定数が使用されます。初期スコアを T スコアに変換する式は次のとおりです。
t = 50 + 10 -------
標準化手順の意味を例を用いて見てみましょう。 販売員のコミュニケーション スキルと店舗の立地の特殊性との間の関連性に興味があるとします。 大都市。 特定の売り手のコミュニケーションスキルを総合的に評価するために、観察を通じて、各被験者について買い手とのコミュニケーションを特徴づけるパラメータの数を取得することができます。 たとえば、アイコンタクトの平均時間、一定時間内の笑顔の平均数、無礼で無愛想な態度の数などを測定できます。 市内の店舗の立地の長所と短所 (その場所の混雑度など) を特徴付けることができます。 これを行うには、店舗のすぐ近くに停車する公共交通機関のルートの数を数えたり、地下鉄の駅からの距離を推定したり、近くにある異なるプロファイルの店舗の数を考慮したりすることができます。
一般化されたコミュニケーション指標を導き出すために、笑顔の数とアイコンタクトの継続時間を加算し、この合計から低言語文化を示す表現の数を引くことは不可能です。 バス路線の数と近隣の店舗の数を加算し、その合計から最寄りの地下鉄までの距離を引くことは意味がありません。 多数の店舗で調査を実施して必要な定量データを収集し、これらすべての指標について一次統計を計算し、初期データを変換した後、各指標の T スコアを取得する方がよいでしょう。
正規化する場合、データ収集中に初期単位で取得された各値から算術平均が減算され、その差がシグマで除算されます。 結果の値は 10 倍され、50 に加算されるか、50 から減算されます。最後の算術演算 (加算または減算) を選択することにより、このパラメータが計算された積分推定値に与える影響の方向を設定できます。 このパラメータの詳細を考慮して、変換の方向を設定できます。 初期単位の特定の値が算術平均を超える場合は、正規化された偏差 (差をシグマで割ったもの) を 50 に加算できます。これは、この被験者の評価された精神的質の重症度がサンプルの平均よりも大きいことに対応します。
たとえば、特定の販売者のシグマごとの笑顔の数 (平均よりも多い) は、60 T ポイントとして定量的に表現されるようになります。 高値の兆候の定量的評価 言論文化正規化された偏差は 50 T ポイントに加算され、低言語文化は 50 T ポイントから減算される必要があります。 たとえば、負の方向の何らかの兆候の定量的評価(初期点)が超過した場合、 平均値この種の変換の後、特定の主題のコミュニケーションスキルの統合指標を計算するときに、いくつかの T ポイントを他の主題に加算することができます。
データの標準化の形式は、最初に得られる推定値の範囲や階調数などを考慮して選択するとよいでしょう。 初期スコアの階調数が 7 ~ 15 の場合、ステニンが非常に適している可能性があります。 2 。 階調数が 30 以上に達し、分布がわずかに歪んでいる (非対称) 場合、これらの指標をステニンに変換することでスコアを粗くします。 測定精度の一部が失われます。 測定が非常に効果的であると信じる理由がある場合(たとえば、テストと再テストの信頼性が良好であるという証拠がある、測定で得られた指標と明確で信頼できる外部検証基準との高い相関関係が見つかっているなど)、同じまたは少し多い階調数を持つ標準化された単位を使用すること。
信頼性の標準化とは、規制文書および技術文書における信頼性に関する定量的および定性的な要件の確立を指します。 信頼性の標準化には、次の一連の対策が含まれます。
一連の標準化された信頼性指標の選択。
オブジェクトとそのコンポーネントの信頼性指標の値の実現可能性調査。
ソースデータの正確性と信頼性に関する要件を設定する。
故障、損傷、限界状態の基準の作成。
すべての段階で信頼性管理手法の要件を設定する ライフサイクル物体。
GOST 27.003-83 で提案されている一連の指標から標準化された信頼性指標を選択することをお勧めします。 施設の責任、運転条件、起こり得る故障の影響、運転コスト、その他の要因を考慮して、この GOST に含まれていないが矛盾しない指標を適用することができます。 このような決定は通常、機器メーカーと施設の顧客との間の合意によって行われます。
標準化された信頼性指標の値は、物品の価格を決定するとき、メーカーによる保証義務を割り当てるとき、および認可するときに非常に重要です。 紛争状況運用中のメーカーと顧客の間の。
標準化された信頼性指標の命名法を選択するときは、通常、その曖昧さのなさ、明確な物理的意味、設計時および動作時の確認時の計算の可能性を追求します。 選択するときは、オブジェクトの重要性、その操作の条件とコスト、および失敗の影響の深刻さが考慮されます。
オブジェクトの動作に対する保証期間を確立する場合、標準化された信頼性指標の値が重要な役割を果たします。 信頼性や耐久性が高いものほど保証期間を長く設定できます。 同時に、オブジェクトのコストも増加するはずです。 保証動作時間または保証保管期間は、隠れた欠陥を特定して排除するのに十分な期間でなければなりません。
信頼性指標の選択と標準化は、GOST 27.003-83 3に従って実行されます。 さまざまな信頼性指標の選択は、オブジェクトの要件の開発から始まり、その要件はその作成のための技術仕様の形で作成されます。 オブジェクトが標準設計に従って作成された場合、技術仕様には、一般的な技術標準、技術条件 (TU)、および部門別の規制文書 (SNiP など) に規定されている信頼性要件が含まれます。
技術仕様の「信頼性要件」セクションには次のように記載されています。
耐久性と保存の要件が確立される対象の限界状態の基準。
オブジェクトの失敗基準。
「効率維持係数」という指標を用いて信頼性要件が定められている対象に対する概念「出力効果」の定義。
技術仕様の「管理方法(試験、分析、測定)」のセクションには、信頼性指標を監視するための初期データが示されています。 また、「使用上の注意(使用方法)」では、保守システムの特徴や保守機器の要件について説明します。
技術仕様には、計測学的サポートの要件と、信頼性要件への準拠を保証する必要がある動作条件およびモードの特性が必ず含まれている必要があります。
一般に、確立された規制文書 (標準、仕様、技術仕様、設計標準など) がない場合、信頼性指標の範囲を決定するために、GOST 27.003-83 はオブジェクトを 2 つのグループに分割することを規定しています。この 2 つのタイプは区別されます。 最初のグループ (I) には、効率基準が確立されており、障害の結果と効率への影響の性質がわかっているすべてのオブジェクトが含まれます。 他のすべてのオブジェクトは 2 番目のグループ (II) に属します。
各グループにおいて、最初のタイプ (1) のオブジェクトには、動作可能状態と動作不能状態を分離する基準がわかっているオブジェクトが含まれており、動作中のオブジェクト自体はこれらの状態の 1 つのみになる可能性があります。 他の場合、オブジェクトは 2 番目のタイプ (2) として分類されます。
耐久性インジケーターを選択する場合、タイプ 1 オブジェクトには、限界状態の基準を明確に確立できるオブジェクトが含まれます。 他の場合、オブジェクトはタイプ 2 として分類されます。
信頼性指標の命名法
表1。
|
オブジェクトのグループ |
オブジェクトの種類 |
インジケーターの命名法 |
||||||
|
信頼性 |
耐久性 |
保守性 |
保存性 |
複雑な |
||||
|
T R、TR %; T SL、TSL % |
S または S その後 (S P) または S B |
Т С (Т С %) |
特別なケース |
|||||
|
耐久性の指標 コンポーネント |
S または S その後 (S P) または S B |
Т С (Т С %) | ||||||
表 1 の続き。
|
回復不可能 回復可能 |
T CP または T % または (t)またはP(t) |
S または S その後 (S P) または S B |
Т С (Т С %) | |||||||
|
TO or(t) |
T R (TR %)、TSL (TSL %) |
Т С (Т С %) | ||||||||
|
主要コンポーネントの信頼性指標 | ||||||||||
表 1 に示すように、グループ I、タイプ 1 のオブジェクトの場合、効率係数 K EF ( 特別なケース効率保持係数)は、耐久性と保存期間の最も広く代表される指標です。 耐久性指標の範囲は、次の要素を考慮して選択されます。
オブジェクトが限界状態に達した場合に考えられる結果。
技術的状態を監視し、残存寿命を予測するための既存および計画された手段および方法の有効性。
類似物体の操作経験または物理的前提条件から予想される、操作中に製品の技術的状態を変更するための主なメカニズム。
限界状態に達したオブジェクトを復元する基本的な可能性と、大規模な修復を実行するための計画された方法 (非人間的かどうかに関係なく)。
このグループのオブジェクトでは、動作負荷の影響下でのみパフォーマンスの損失が発生するため、平均耐久性を指標として設定することをお勧めします。 T R(ガンマ – パーセンテージ T R % ) リソース。 それ以外の場合は寿命を設定してください T SL 、T SL % .
非個人的な方法でオーバーホールされるオブジェクトについては、最初の修理前、修理の間、および償却前のリソース (耐用年数) を特徴付ける耐久性指標が設定されます。
例として、グループ II、タイプ 1 の修復不可能なオブジェクトの信頼性指標の別の命名法を考えてみましょう。表 1 からわかるように、信頼性指標を設定するには、平均故障時間 T SR、またはガンマを使用することが推奨されます。 - 障害が発生するまでの時間の割合 T %、または障害率 ( t)、または障害のない操作の確率 P(t) オブジェクトの限界状態に達することが必ずしも障害に関連していない場合は、障害のない動作も伴います。動作インジケーター 耐久性インジケーター - 平均またはガンマ - リソース (耐用年数) の割合を設定することができます。
標準化の概念には、さまざまな信頼性指標の選択に加えて、信頼性標準の選択も含まれます。 これらは以下を考慮して選択されます。
国内外の類似品の信頼性を高めるための達成レベルと特定された傾向。
科学的な研究開発作業の結果。
業界の技術的および経済的機会。
信頼性指標の基準は、物体の質量、体積、コストに関する既存の制限を考慮して選択する必要があります。 これらは、オブジェクトの開発、製造、運用、修理の総コストを最小限に抑えながら所定の効率の基準に従って、または固定の総コストで最大の効率を達成するという基準に従って最適化する必要があります。
信頼性の基準は、技術仕様書や技術仕様書に定められた対象物の使用形態や動作条件に関連して定められています。 これらの基準は、施設の構成要素の信頼性基準と、構成部品の供給者の保証義務に関連付けられている必要があります。 基準の確立には、その達成可能性の経済分析、最適性の専門家による評価、および選択された基準と政策文書との適合性の確認を含む特定の科学的研究作業が先行する必要があります。
重要なオブジェクトについては、個別の指標を設定し、それに応じて個別の信頼性基準を設定することができます。 この場合、すべての信頼性指標には「確立された」という特別な名前が付けられます。 確立されたリソース、確立された障害までの時間など。 固有のオブジェクトおよび(または)クリティカルなオブジェクトの信頼性指標の選択と標準化も、関連する推奨事項を提供する GOST 27.003-83 に従って実行されます。
個別の(確立された)信頼性指標を持つオブジェクトは、確立された動作時間または確立された耐用年数が経過する前に故障した(または限界状態に達した)ものであり、信頼性基準に従って非標準とみなされます。 オブジェクトの個々のパフォーマンス指標にも同じことが当てはまります。