Нормирование (стандартизация) и унификация данных. Нормирование - новый хорошо забытый инструмент управления
Нормирование (стандартизация) и унификация данных
Нормированные (стандартизованные) данные. В ряде задач бывает удобно или даже необходимо перейти от исходных наблюдений, где i = 1, 2,.... п, к нормированным (стандартизованным), которые введем далее. Пусть имеются данные, на основании которых получены
![]()
Нормированными (стандартизованными ) называют данные вида
– безразмерные величины, удовлетворяющие условию
Покажем, что средняя арифметическая нормированных данных равна нулю:
а дисперсия равна единице:
При этом если нормированная величина больше нуля (.г* > 0), то наблюдаемое значение больше среднего (х ; > х). Если же х" < 0, то х, < х.
Стандартизация (нормирование) данных является необходимым начальным этапом преобразования данных при использовании многих многомерных статистических методов – снижения размерности признакового пространства (факторный, компонентный анализ, см. гл. 5), классификации объектов (кластерный анализ, см. гл. 6) и др., особенно если переменные измерены в шкалах, существенно различающихся в величинах (микроны единиц – миллиарды единиц).
Вследствие распространенности и востребованности в статистических пакетах процедура нормирования (стандартизации) обычно вынесена в меню (рис. 1.31).

Рис. 1.31. Вызов процедуры нормирования (стандартизации) данных в меню пакета STA TISTICA (StatSoft)
Унификация данных (унифицированная шкала). При построении интегральных обобщающих показателей часто возникает ситуация, когда нормирование данных не дает нужного результата. Например, нам необходимо построить интегральный показатель качества жизни в стране (регионе) , включающий в себя три исходные переменные – продолжительность жизни, младенческую смертность и уровень безработицы. При этом, даже переведя эти три показателя в единую шкалу (например, со значениями от 0 до 1 или от 0 до N), мы будем иметь конфликт в интерпретации переменных следующего плана.
Первая переменная – продолжительность жизни – характеризуется тем, что чем большие значения она принимает, тем выше качество жизни в стране (регионе). Напротив, вторая переменная – младенческая смертность – при повышении значений понижает качество жизни. Третья переменная – безработица – имеет свой некоторый оптимум (примерно 5% обеспечивает нормальное функционирование и развитие экономики ). И, соединив все три признака в один интегральный показатель, мы будем иметь отсутствие адекватной интерпретации полученного показателя. Чем он выше, тем выше продожительность жизни (лучше), выше младенческая смерность (хуже), выше безработица (непонятно). Для разрешения таких проблем и существует при анализе данных способ, позволяющий это сделать, – приведение всех переменных, участвующих в построении интегрального показателя, к единой унифицированной шкале.
Унифицированная шкала – используемая при построении интегральных показателей из различных переменных шкала, принимающая значения от 0 до N имеющая единую систему интерпретации: чем выше значения переменной в унифицированной шкале, тем выше значение интегрального показателя. При N = получаем шкалу от 0 до 1.
Переменные первого типа – чем выше показатель, тем лучше (продолжительность жизни) – приводятся к унифицированной шкале следующим образом:
где Xj – значение переменной для г-го наблюдения; amin и атах – соответственно наименьшее и наибольшее наблюдаемые значения переменной.
Согласно этой формуле если x t – amin, то а" =0, а если.г, – апт, то х] = N, т.е. чем больше значение переменной а, тем выше (лучше) ее значение в унифицированной шкале а*.
2. Переменные второго типа – чем выше показатель, тем хуже (младенческая смертность) – приводятся к унифицированной шкале следующим образом:
Согласно этой формуле если а, = ат|1), го х = N, а если а,- = а„их, то а* = 0, т.е. чем больше значение переменной а, тем ниже (хуже) ее значение в унифицированной шкале X/.
3. Переменные третьего типа – показатель имеет некий оптимум аопт, это значение наилучшее, чем больше отклонения от него, тем хуже (уровень безработицы) – приводятся к унифицированной шкале следующим образом:
Согласно этой формуле если x t = аопт, то х] = N. Если же а, имеет максимально возможное отклонение оташп, то а," =0. Например, если (ашах – а,шт) > > (aOMT-amin) и а, = атах, то а" =0. Таким образом, чем больше значение переменной а, отклоняется от оптимального, тем ниже (хуже) значение а* в унифицированной шкале, а чем ближе значение а, к этому аопт, тем лучше.
- Айвазян С. А. Анализ качества и образа жизни населения // ЦЭМИ РАН. М.: Наука, 2012. (Экономическая наука современной России).
- Там же.
Почему нужна нормировка показателя
Обычно выраженность некоторого качества пытаются описать числом. Чаще всего такое число х формируется как сумма баллов. Насколько это правомерно — вопрос другой. Мы же предположим, что такое число х получено и осмысленно.
Обычно х меняется от некоторого минимального значения x min (отражающего отсутствие качества) до некоторого максимального значения x max (крайняя степень проявления, наличия, выраженности, …).
Его получение решает проблему сравнения двух объектов, но только по этому показателю. Впрочем, и здесь дело не очень хорошо. Надо всегда помнить, в каких пределах меняется показатель. А эти диапазоны — самые разнообразные… Да еще и оценивать, насколько близко конкретное значение к краям диапазона или к его середине. В общем, чистая морока.
Если же речь идет о сравнении по двум различным показателям — дело совсем швах. Конечно, нельзя сравнивать качества непосредственно. Для этого сравниваемые числа должны быть безразмерными. А ведь именно показатель обычно интерпретируется как степень выраженности некоторого качества. И вот это сравнивать можно!!! Но для этого их следует привести к одной шкале так, чтобы начала и концы двух шкал совпадали.
Но почему только этих двух? Давайте сделаем такое преобразование для всех показателей! Оно и называется нормировкой (не путать с нормализацией !). После этого мы можем сравнивать разнообразные показатели, полученные различными методиками.
2. Типы показателей
При всем разнообразии числовых характеристик объектов (или респондентов) из них можно выделить два широких класса:
- униполярные , выражающие только степень наличия (интенсивность, выраженность, …) некоторого качества;
- биполярные , отражающие не только степень наличия качества, но и его «направленность».
3. Нормировка униполярного показателя
Давно сложилось в науке так, что величины нормируются на диапазон от 0 до 1.
Для этого функция преобразования y=f(x) должна обладать следующими свойствами:
y(x min)=0; y(x max)=1; dy/dx>0 (1)
Любая функция с такими свойствами м.б. использована для нормировки. Например, если x max , то можно выбрать функцию
![]()
Легко видеть, что за счёт выбора соответствующей функции можно учесть разнообразные эффекты искажения оценок. Например, склонность респондента к крайним оценкам. При этом, возможно, следует применять для различных респондентов и различные функции преобразования, учитывающие особенности их личности, статуса и т.п. Примерные графики таких функций — на рис. 1.

Рис. 1. Графики функции нормировки
Наиболее часто применяется линейное преобразование:
![]() (2)
(2)
Если полагать, что увеличение х описывает как возрастание выраженности качества А, так и убывание степени некоторого другого качества В, то нормированной мерой качества В может служить просто разность y´=1–y. Таковы, например, родственные по смыслу качества ‘близость’ и ‘дистанция’. Их метризация выявляет плохо осознаваемую ранее, но вполне четкую дополнительность и даже противоположность.
4. Нормировка биполярного показателя
Обычно такой показатель представляет собой ‘склейку’ двух взаимопредполагающих и антонимичных униполярных качеств А и В.
Часто В есть просто отрицание А и наоборот. По такому принципу построены, например, шкалы семантического дифференциала. Однако, пары для такого дифференциала следует проверить по словарю антонимов (например, два антонима к слову «веселый» – «грустный» и «мрачный» – вовсе не являются синонимами).
Нормировка соответствующей величины предполагает выбор «положительного » направления оси y. В качестве такового произвольно выбирается тот из полюсов шкалы, увеличение интенсивности которого принимается как возрастание y. Противоположный полюс автоматически становится «отрицательным ». Подчеркнем, что никакой модальности (аксиологической оценки) за этим нет - играть роль могут только сложившиеся смысловые стереотипы, но не более того.
Пусть величина х оценивает степень выраженности обоих качеств (с соответствующим обозначением, например, ‘очень люблю’ или ‘слегка ненавижу’). Нормировку можно проводить при помощи любой функции, удовлетворяющей условиям (1). В частности, это м.б. и линейное преобразование:
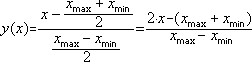 (3)
(3)
Очевидно, что y[–1; +1].
Обе формулы (2) и (3) описывают линейное преобразование вида y=k·x+b. Поэтому все статистические выводы относительно величин x и y полностью совпадают .
5. Особенности балльных шкал
При использовании балльной шкалы имеется несколько тонкостей, которые часто упускаются из виду:
- Иногда нет ответов на все вопросы, относящиеся к данному показателю. Причины разные — ответ просто не дан, ошибка при внесении ответа или его кодировке, … Короче — имеются пропуски ответов.
- Практически всегда балл приравнивается к номеру ответа среди прочих. И наименьший балл становится равным 1.
- Хотелось бы использовать для некоторых вопросов ответ с числом градаций, отличающимся от остальных. Но тогда его вклад надо учитывать как-то по-другому.
При нормировке балльной шкалы надо всего лишь принять, что х = S, где S сумма набранных баллов по полученным ответам (а не заданных вопросов!). Соответственно, S min и S max — минимальная и максимальная суммы баллов, которые можно набрать при полученных ответах.
Сами значения рассматриваемого критерия непригодны для оценки связи между признаками, поскольку они зависят от объема выборки и других обстоятельств, носящих, вообще говоря случайный характер по отношению к силе измеряемой связи (о некоторых обстоятельствах подобного рода пойдет речь ниже). Так, величина критерия, например, равная 30, может говорить о большой вероятности наличия связи, если в клетках исходной частотной таблицы стоят величины порядка 10,20,30, и о ничтожной вероятности того же, если рассматриваемые частоты равны 1000, 2000, 3000 и т.д. В таких случаях возникает необходимость определенной нормировки найденного значения критерия – такого его преобразования, которое устранит описанную зависимость от случайных (для оценки связи) факторов.
Подчеркнем, что здесь речь идет о принципиальном моменте, часто возникающем при использовании в социологии разного рода статистических критериев, индексов и т.д. Всегда необходимо выяснять, не отражает ли используемый показатель что-либо случайное по отношению к изучаемому явлению и в случае наличия такого отражения осуществлять соответствующую нормировку показателя.
Принято нормировку, подобную описанной, осуществлять таким образом, чтобы нормированные коэффициенты изменялись либо от -1 до +1 (если имеет смысл противопоставление положительной и отрицательной направленности изучаемого с помощью рассматриваемого индекса явления, в нашем случае - связи), либо от 0 до 1 (если выделение положительной и отрицательной направленности явления содержательно бессмысленно).
Почеркнем, что приведение всех коэффициенту к одному и тому же интервалу является необходимым, но не достаточным условием, обеспечивающим возможность их сравнения. Если такого приведения не будет сделано, сравнение заведомо невозможно. Но и при его осуществлении сравнение тоже может оказаться бессмысленным. Об этом пойдет речь в п. 2.3.5.
Имеются разные подходы к требующейся нормировке. Наиболее известными являются такие, которые превращают критерий “Хи-квадрат” в известные коэффициенты, называемые обычно по именам впервые предложивших их авторов - Пирсона, Чупрова, Крамера. За этими коэффициентами утвердились постоянные обозначения, отвечающие первым буквам названных фамилий (коэффициент Чупрова отвечает немецкому tsch, коэффициент Крамера имеет два обозначения из-за известного различия букв, обозначающих звук “к” в разных языках):


Опишем некоторые свойства этих коэффициентов. Начнем с тех, которые обычно оговариваются в литературе.
Все коэффициенты изменяются от 0 до 1 и равны нулю в случае полной независимости признаков (в описанном выше смысле). Как и критерий “хи-квадрат”, эти показатели являются симметричными относительно наших признаков: с их помощью нельзя выделить зависимую и независимую переменную, на основе их анализа нельзя говорить о том, какая переменная на какую "влияет".
Обычно в качестве недостатка коэффициента Пирсона Р (предложенного в литературе первым) упоминается зависимость его максимальной величины от размера таблицы (максимум Р достигается при c=r, но величина максимального значения изменяется с изменением числа категорий: при с=3 значение Р не может быть больше 0,8, при с=5 максимальное значение Р равно 0,89 и т.д. [ Интерпретация и анализ..., 1987. С.31]). Естественно, это приводит к возникновению трудностей при сравнении таблиц разного размера.
Отметим следующий немаловажный факт, очень редко рассматривающийся в ориентированной на социолога литературе.
Многие свойства рассматриваемых коэффициентов доказываются лишь при условии выполнения одного не всегда приемлемого для социологии предположения, состоящего в том, что за каждым нашим номинальным признаком "стоит" некая латентная (скрытая) непрерывная количественная (числовая) переменная.
Сделаем небольшое отступление по поводу используемых терминов. Все три определения к термину "переменная" требуют пояснения. Термин "латентная" употребляется здесь несколько условно. Обычно (в теории социологического измерения, например, в факторном, латентно-структурном анализе, многомерном шкалировании) под латентной переменной понимают признак, значения которого вообще не поддаются непосредственному измерению (например, путем прямого обращения к респонденту). Значения же нашей переменной мы измеряем самым непосредственным образом. Но получаем при этом номинальную шкалу, хотя и предполагаем, что между отвечающими этим значениям свойствами реальных объектов существуют отношения, достаточно сложные для того, чтобы можно было говорить об использовании интервальной шкалы (о соотношении между "богатством" реальных отношений между эмпирическими объектами и типом шкал, использующихся при шкалировании этих объектов, см., например [Клигер и др., 1978; Толстова, 1998]).
Термин "непрерывная" здесь употребляется в том смысле, что в качестве значения этой переменной может выступать любое рациональное число.
"Количественной" мы, в соответствии с традицией, называем переменную, значения которой получены по шкале, тип которой не ниже типа интервальной шкалы (о нашем отношении к подобному использованию терминов "качественный - количественный" уже шла речь в п.4.3 части I). Можно показать, что для таких шкал любое рациональное число может в принципе оказаться шкальным значением какого-либо объекта. Поэтому термины "количественный" и "непрерывный" часто употребляются как синонимы.)
Итак, мы полагаем, что каждый номинальный признак получен из некоторого количественного в результате произвольного разбиения диапазона его изменения на интервалы, количество которых равно числу значений нашей номинальной переменной. И, задавая респонденту интересующий нас вопрос в анкете, мы как бы принуждаем его разбить весь диапазон изменения рассматриваемой переменной на интервалы и указать, в каком из этих интервалов, по его мнению, находится оцениваемый объект. Внутри каждого интервала значения переменной становятся неразличимыми, между интервалами же определены лишь отношения совпадения – несовпадения (основное свойство номинальной шкалы). Когда исследователь имеет дело с двумя переменными такого рода (например, когда нас интересуют парные связи) то обычно предполагается еще и нормальность соответствующего двумерного распределения.
Именно таких предположений придерживался Пирсон, когда в начале века вводил свой коэффициент. Он доказал, что Р равно тому предельному значению обычного коэффициента корреляции между латентными переменными, к которому этот коэффициент стремится при безграничном увеличении количества градаций рассматриваемых признаков. Ясно, что без указанного предположения было бы совершенно неясно, как подобное свойство коэффициента Р можно проинтерпретировать.
Для исправления указанного недостатка коэффициента Пирсона (зависимости его максимально возможного значения от размеров таблицы сопряженности) Чупров ввел коэффициент Т, названный его именем. Но и Т достигает единицы лишь при c=r, и не достигает при c¹r. Может достигать единицы независимо от вида таблицы коэффициент Крамера К. Для квадратных таблиц коэффициенты Крамера и Чупрова совпадают, в остальных случаях К >Т.
Мы перечислили те свойства рассматриваемых коэффициентов, которые часто упоминаются в литературе. Из редко упоминающихся свойств можно упомянуть еще один свойственный всем коэффициентам недостаток – зависимость их величины от соотношений маргинальных частот анализируемой таблицы сопряженности (подчеркнем очень важный момент – вычисляя теоретические частоты, мы пользуемся маргинальными суммами, полагая, что имеем дело с их “генеральными” значениями, что, вообще говоря, не всегда отвечает реальности).
О том, как можно измерять связь между номинальными признаками с помощью критерия “Хи-квадрат”, можно прочесть в работах [Елисеева, 1982; Елисеева, Рукавишников, 1977, с.82-89; Интерпретация и анализ..., 1987, с.31-32; Лакутин, Толстова, 1990; Паниотто, Максименко, 1982, с.65-84; Рабочая книга социолога, 1983, с.169-172, 190 (с учетом того, что на с, 169 речь идет о таких теоретических частотах, которые являются частотами таблицы сопряженности, отвечающей случаю статистической независимости рассматриваемых номинальных переменных); Статистические методы..., 1979, с.117-120; Толстова, 1990а, с.54-57]
Проиллюстрируем значение использования норм на примере широко известной методики К.Томаса. Напомним, что в ней вывод о доминирующей стратегии поведения в конфликтной ситуации делается с опорой на числовые данные. А именно, после подсчета суммарных баллов по каждой шкале, нужно выявить шкалу имеющую наибольший балл. Соответствующая шкале стратегия интерпретируется как доминирующая в конфликтной ситуации. Подсчитанные статистики показывают, что средние величины шкальных оценок по абсолютной величине различны. Они варьируют у мужчин от 5,25 балла до 7,25 балла и у женщин от 3,71 до 7,65 баллов (см. табл. 11).
Табл. 11. Первичные статистики шкальных оценок методики Томаса
|
Мужчины (n=56) |
Женщины (n=71) |
|||||||
|
Стратегия | ||||||||
|
Напористость | ||||||||
|
Сотрудничество | ||||||||
|
Компромисс | ||||||||
|
Избегание | ||||||||
|
Уступчивость | ||||||||
Примечание.
Средн. - средние величины;
950% и +95.0% - доверительные интервалы средних величин;
Выделены наибольшие средние величины.
Таким образом, если не учитывать нормативные данные, полученные на российской выборке (или проверенные на российской выборке), то в интерпретации результатов можно придти к неверным выводам. В самом деле, мужчинам и женщинам свойственно предпочтение стратегии избегания. В руководстве к методике не говорится о том, что доминирование одной из пяти стратегий является транскультуральной характеристикой личности. По контексту можно понять, что автор исходит из предположения о равной вероятности предпочтения каждой из пяти стратегий. Поскольку между шкальными показателями существуют статистически значимые корреляционные связи, вряд ли можно говорить о равной вероятности следования каждой из пяти стратегий. В такой ситуации, когда отсутствуют нормативные данные и сведения о характере распределения величин, надежнее опираться на подсчитанные для своей выборки статистики. В частности - для оценки выраженности доминирования одной из стратегий использовать сигму и доверительные интервалы. Добавим, что нормы целесообразно рассчитать отдельно для мужчин и женщин. По представленным данным видно, что в двух шкалах из пяти показатели значимо различаются у разных полов. При сравнении групп или подгрупп, эта половая специфичность может оказаться переменной, влияние которой нельзя не учитывать.
Вычислять нормы целесообразно и в других случаях. Полученные при сборе данных начальные (первичные) оценки выполнения экспериментальных заданий далеко не всегда удобно использовать в дальнейшей работе. Их тем или иным способом преобразуют. Наиболее частыми преобразованиями являются центрирование и нормирование среднеквадратическими отклонениями. Под центрированием понимается линейная трансформация величин признака, при которой средняя величина распределения определенного признака становится равной нулю. Направление шкалы и ее единицы остаются при этом неизменными.
Суть нормирования состоит в переходе к другому масштабу - стандартизированным единицам измерения. При стандартизировании результатов тестовых испытаний нормирование чаще всего осуществляется с помощью среднеквадратических отклонений. Стандартизирование производится при нормальном распределении тестовых оценок или близком к нему по виду.
В психологии существует целый ряд шкал, основанных на нормальном распределении и имеющих разные значения М и . Например, в шкале отклонений интеллекта IQ: М=100, =15; в шкале Векслера М=10, = 3. Распределения различных измеренных в эксперименте признаков имеют разные величины М и . Переводя полученные первичные оценки разных признаков к распределению с одними и теми же М и , мы получаем больше возможностей для оценки и сопоставления их варьирования. Сделать это нам позволяет использование нормированного отклонения. Нормированное отклонение показывает, на сколько сигм отклоняется та или иная варианта от среднего уровня варьирующего признака (средней арифметической), и выражается формулой:
где V - значение признака (в начальных баллах).
С помощью нормированного отклонения можно оценить любое полученное значение по отношению к группе в целом, взвесить его отклонение и одновременно освободиться от именованных величин. Для того чтобы избавиться от отрицательных чисел к полученной величине t можно прибавить какую-либо константу. Удобно, если все числа, с которыми вы оперируете имеют одинаковое количество знаков. С учетом этих соображений весьма удобна шкала Т-оценок. Для этой шкалы принято нормальное распределение, имеющее М=0, =10. Для пересчета берется константа равная 50. Формула преобразования начальных баллов в Т-оценки следующая:
t = 50 + 10 -------
Смысл процедуры нормирования рассмотрим на примере. Предположим, нас интересуют некоторые связи коммуникативной умелости продавцов с особенностями расположения магазина в крупном городе. Чтобы составить некоторую интегральную оценку коммуникативной умелости конкретного продавца, мы можем через наблюдение получить по каждому испытуемому ряд параметров, характеризующих его общение с покупателем. Например, мы можем измерить среднюю длительность контакта глазами, среднее количество улыбок в фиксированный интервал времени, количество грубых, неприветливых обращений и т.д. Можно охарактеризовать преимущества и недостатки расположения магазина в городе (насколько "бойкое место" и т.п.). Для этого можно подсчитать количество маршрутов городского транспорта, имеющих остановки в непосредственной близости от магазина, оценить его удаленность от станций метро, учесть число расположенных поблизости магазинов другого профиля и т.д.
Для того чтобы вывести некоторый обобщенный коммуникативный показатель невозможно складывать число улыбок с длительностью контакта глазами и вычитать из этой суммы количество выражений, свидетельствующих о низкой речевой культуре. Бессмысленно складывать число автобусных маршрутов с числом соседних магазинов и вычитать из суммы величину расстояния до ближайшего метро. Лучше собрать необходимый массив количественных данных, проводя исследование в ряде магазинов, подсчитать первичные статистики для всех этих показателей, а затем, после преобразования начальных данных, получить Т-баллы по каждому показателю.
При нормировании из каждого полученного при сборе данных значения в начальных единицах вычитают среднюю арифметическую, а разность делят на сигму. Полученную величину умножают на 10, затем прибавляют к 50 или вычитают из 50. Выбором последнего арифметического действия (сложение или вычитание) мы можем задать направление вклада, который делает этот параметр в высчитываемую интегральную оценку, т.е. можем задавать направленность преобразования, учитывая специфику данного параметра. Если конкретное значение в начальных единицах превышает среднюю арифметическую, мы можем нормированное отклонение (разность, деленную на сигму) приплюсовать к 50. Это будет соответствовать большей выраженности оцениваемого психического качества у данного испытуемого, чем в среднем по нашей выборке.
Например, большее у конкретного продавца количество улыбок на одну сигму (чем в среднем) количественно теперь будет выражено: 60 Т-баллами. Количественную оценку признаков высокой речевой культуры в нормированных отклонениях следует прибавлять к 50 Т-баллам, а низкой речевой культуры - вычитать из 50 Т-баллов. Если, например, количественная оценка некоторого признака отрицательной направленности (в начальных баллах), превышает среднюю величину на полсигмы, то в Т-баллах она будет равна 45. После такого рода преобразований, подсчитывая интегральный показатель коммуникативной умелости для конкретного испытуемого, мы можем прибавлять одни Т-баллы к другим.
Форму стандартизирования данных целесообразно выбирать с учетом размаха полученных начальных оценок и числа градаций. Если в начальных баллах число градаций 7-15, то могут оказаться вполне подходящими стенайны 2 . Если же число градаций достигает 30 и более при небольшой скошенности распределения (асимметрии), то переводя эти показатели в стенайны мы будем огрублять баллы, т.е. терять некоторую долю точности произведенного измерения. Если есть основания считать, что ваши измерения достаточно эффективны (например, есть данные о хорошей ретестовой надежности, обнаружены высокие корреляции полученных в измерениях показателей с ясными и надежными внешними критериями валидизации и т.д.), то оправданным будет использование стандартизированых единиц имеющее такое же или даже несколько большее число градаций.
Нормированием надёжности называют установление в нормативно – технической документации количественных и качественных требований к надёжности. Нормирование надёжности включает комплекс мероприятий:
Выбор номенклатуры нормируемых показателей надёжности;
Технико-экономическое обоснование значений показателей надёжности объекта и его составных частей;
Задание требований к точности и достоверности исходных данных;
Формирование критериев отказов, повреждений и предельных состояний;
Задание требований к методам контроля надёжности на всех этапах жизненного цикла объекта.
Нормируемый показатель надёжности рекомендуется выбирать из совокупности показателей, предложенных в ГОСТ 27.003-83. С учётом ответственности объекта, условий эксплуатации, последствий возможных отказов, затрат на эксплуатацию и других факторов могут быть применены показатели не включённые в этот ГОСТ, но не противоречащие ему. Такое решение обычно принимается по согласованию между производителем техники и заказчиком объекта.
Величины нормируемых показателей надёжности имеют большое значение при определении стоимости объекта, при назначении изготовителем гарантийных обязательств, а также при разрешении конфликтных ситуаций между изготовителем и заказчиком в процессе эксплуатации.
При выборе номенклатуры нормируемых показателей надёжности обычно стремятся к их однозначности, явному физическому смыслу, возможности расчёта при проектировании и подтверждения в эксплуатации. При выборе учитывают важность объекта, условия и стоимость его эксплуатации, а также тяжесть последствий отказа.
При установлении гарантийного срока эксплуатации объекта важную роль играют значения нормируемых показателей надёжности. Чем выше безотказность и долговечность объекта тем большим может быть установлен гарантийный срок эксплуатации. Одновременно должна возрастать стоимость объекта. Длительность гарантийной наработки или гарантийного срока хранения должны быть достаточными для выявления и устранения скрытых дефектов.
Выбор и нормирование показателей надёжности выполняется в соответствии с ГОСТ 27.003-83 3 . Выбор номенклатуры показателей надёжности начинается с разработки требований к объекту, которые оформляются в виде технического задания на его создание. Если объект создаётся по типовому проекту, то техническое задание содержит требования по надёжности, изложенные в общетехнических стандартах, технических условиях (ТУ), а также в ведомственных нормативных документах (например, СНиП).
В технических условиях, в разделе «Требования к надёжности» приводят:
Критерии предельного состояния объектов, применительно к которым установлены требования к долговечности и сохраняемости;
Критерии отказов объектов;
Определение понятия «выходной эффект» для объектов, применительно к которым требования к надёжности установлены с использованием показателя «коэффициент сохранения эффективности».
В разделе ТУ «Методы контроля (испытания, анализа, измерений)» указывают исходные данные для контроля показателей надёжности. А в разделе «Указания по эксплуатации (применению)» излагается характеристика системы технического обслуживания, а также требования к средствам технического обслуживания.
Технические условия должны обязательно содержать требования по метрологическому обеспечению и характеристику условий и режимов эксплуатации, в которых должно быть обеспечено выполнение требований по надёжности.
В общем случае при отсутствии установившихся нормативных документов (стандартов, ТУ, технических заданий, норм на проектирование и т.п.) для определения номенклатуры показателей надёжности ГОСТ 27.003-83 предусматривает подразделение объектов на две группы, в каждой из которых выделяют два вида. К первой группе (I) относят все объекты, для которых установлены критерии эффективности, известны последствия отказов и характер их влияния на эффективность. Все остальные объекты относят ко второй группе (II).
В каждой группе к объектам первого вида (1) относят те, для которых известны критерии разделения работоспособного и неработоспособного состояний, а сами объекты в процессе эксплуатации могут находиться только в одном из этих состояний. В остальных случаях объекты относят ко второму виду (2).
При выборе показателей долговечности к объектам вида 1 относят те, для которых могут быть однозначно установлены критерии предельного состояния. В остальных случаях объекты относят к виду 2.
Номенклатура показателей надёжности
Таблица 1.
|
Группа объектов |
Вид объекта |
Номенклатура показателей |
||||||
|
Безотказность |
Долговечность |
Ремонтопригодность |
Сохраняемость |
Комплексные |
||||
|
Т Р, Т Р % ; Т СЛ, Т СЛ % |
S или S то (S P) или S B |
Т С (Т С %) |
Частный случай |
|||||
|
Показатели долговечности составных частей |
S или S то (S P) или S B |
Т С (Т С %) | ||||||
Продолжение табл.1.
|
Невосстанавливаемые Восстанавливаемые |
Т СР или Т % или (t)или P(t) |
S или S то (S P) или S B |
Т С (Т С %) | |||||||
|
Т О или(t) |
Т Р (Т Р %), Т СЛ (Т СЛ %) |
Т С (Т С %) | ||||||||
|
Показатели надёжности основных составных частей | ||||||||||
Как показано в табл.1, для объектов группы I, вида 1, кроме коэффициента эффективности К ЭФ (частный случай коэффициента сохранения эффективности), наиболее широко представлены показатели долговечности и сохраняемости. Номенклатуру показателей долговечности выбирают с учётом следующих факторов:
Возможных последствий достижения объектами предельного состояния;
Эффективности существующих и планируемых средств и методов контроля технического состояния и прогнозирования остаточного ресурса;
Ожидаемого по опыту эксплуатации объектов-аналогов или из физических предпосылок основного механизма изменения технического состояния изделий в процессе эксплуатации;
Принципиальной возможности восстановления объектов, достигших предельного состояния, и планируемого способа проведения капитальных ремонтов (обезличенного или не обезличенного).
Для объектов этой группы, потеря работоспособности которых происходит только под действием эксплуатационных нагрузок, рекомендуется задавать в качестве показателя долговечности средний Т Р (гамма – процентныйТ Р % ) ресурс. В остальных случаях задают срок службыТ СЛ , Т СЛ % .
Для объектов, капитально ремонтируемых не обезличенным способом, задают показатели долговечности, характеризующие ресурс (срок службы) до первого ремонта, между ремонтами и до списания.
В качестве примера рассмотрим ещё номенклатуру показателей надёжности невосстанавливаемых объектов группы II, вида 1. Как следует из табл.1, для задания показателей безотказности рекомендуется использовать среднюю наработку до отказаТ СР, или гамма – процентную наработку до отказаТ % , или интенсивность отказов(t),или вероятность безотказной работыP(t).Если достижение предельного состояния объектов необязательно связано с отказами, то наряду с показателями безотказности допускается задавать показатели долговечности - средний или гамма – процентный ресурс (срок службы).
Кроме выбора номенклатуры показателей надёжности, в понятие нормирование входит также выбор норм надёжности. Их выбирают с учётом:
Достигнутого уровня и выявленных тенденций повышения надёжности отечественных и зарубежных аналогов;
Результатов научно – исследовательских и опытно – конструкторских работ;
Технико – экономических возможностей промышленности.
Нормы показателей надёжности должны быть выбраны с учётом существующих ограничений массы, объёма и стоимости объекта. Они должны оптимизироваться по критерию заданной эффективности при минимизации суммарных затрат на разработку, изготовление, эксплуатацию и ремонт объектов или – по критерию достижения максимума эффективности при фиксированных суммарных затратах.
Нормы надёжности устанавливают применительно к режиму использования объекта и условиям эксплуатации, указанным в ТУ или в техническом задании. Эти нормы должны быть увязаны с нормами надёжности составных элементов объекта и с гарантийными обязательствами поставщиков комплектующих частей. Установлению норм должна предшествовать определённая научно - исследовательская работа, содержащая экономический анализ их достижимости, экспертную оценку оптимальности, а также проверку соответствия выбранных норм директивным документам.
Для ответственных объектов возможно задание индивидуальных показателей и соответственно индивидуальных норм надёжности. В этом случае все показатели надёжности имеют особое название »установленные», т.е. установленный ресурс, установленная наработка до отказа и т.д. Выбор и нормирование показателей надёжности уникальных и (или) ответственных объектов выполняются также в соответствии с ГОСТ 27.003-83, в котором приводятся соответствующие рекомендации.
Объект с индивидуальными (установленными) показателями надёжности, у которого появились отказы (или достигший предельного состояния) до истечения установленного времени наработки или установленного срока службы, считается нестандартным по критерию надёжности. Это же относится к индивидуальным показателям эффективности объектов.